1、merge以后查看diff
git 做了 merge的时候,比如 当前分支是 dev,需要merge rls的代码
git pull origin rls
做完merge以后,形成了3份代码:新代码、dev原来的代码、rls的代码,需要比较新代码和 dev原代码的不同,也要比较 新代码和 rls的区别
git diff dev
git diff rls
2、merge的时候希望pom文件必选按照某个的
如果做了 merge以后,比如就是希望保留本地的 pom文件,或者就是希望保留 rls的pom文件
这个时候不需要做rebase,只需要
git checkout --ours unisound-commons-time/pom.xml
--ours 表示用 我当前所在分支的版本。
--theirs表示,用另外一个分支的版本
3、结合12的一个案例
比如做了merge虽然没有冲突,但是git diff dev一看,有个文件并不想修改,所以还想保留merge以前的本地(dev)版本
就可以 git checkout --ours **file**
这里的概念 ours和theirs表示 本地和远程 dev 和 rls
4、摘草莓
假如你想删掉一个分支,但是对于里面的一些commit想保留到另一个分支上,这个时候就可以做摘草莓的技术
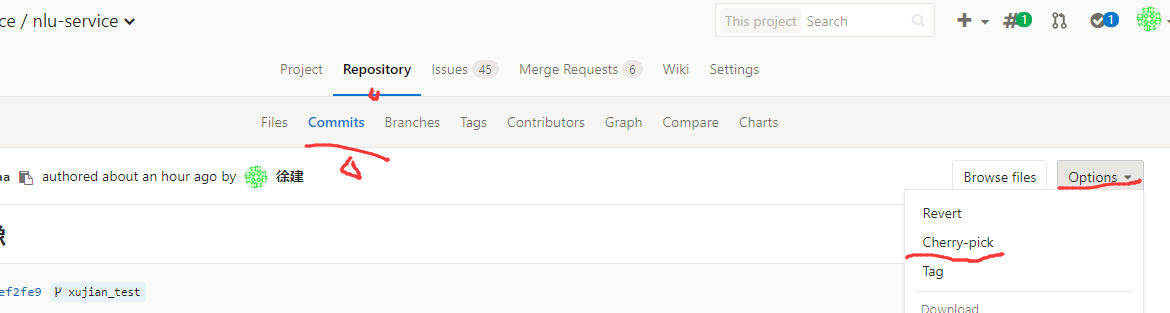
5、从一个commit创建一个分支
git branch **_before_merge 679856aa5
git checkout **_before_merge
git checkout **_before_merge
查看某次commit提交的文件
git show --name-only e893e3175
6、eclipse 换行符
CRLF换行回车是windows使用的行结束符;而LF换行是linux使用的行结束符;所以两者会发生问题。
可以修改eclipse设置使得本地使用linux的行结束符;也可以设置git的参数
core.autocrlf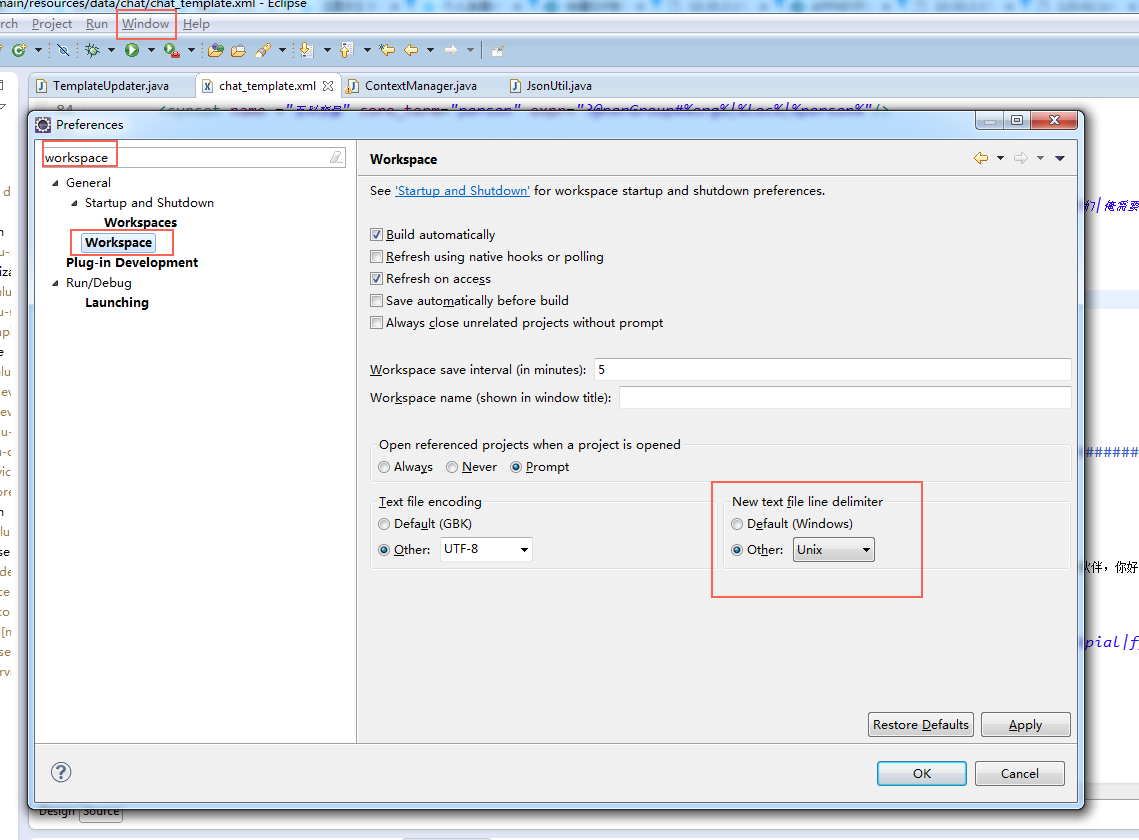
I
官方文档Formatting and Whitespace
core.autocrlf
》》1、如果你在windows编程,但是其他人用非windows编程 you’ll probably run into line-ending issues at some point.
git如何解决这个问题?
git会自动将CRLF换行回车转为LF换行,当你做add a file to index的时候;与此对应,checkout的时候也会将LF换行转为CRLF换行回车需要设置:
$ git config --global core.autocrlf true
》》2、如果你是linux编程,不想git自动行结束符转换,但是如果一个文件意外的行结束符是CRLF你希望git修复他,这个时候使用 core.autocrlf为input
If you’re on a Linux or Mac system that uses LF line endings, then you don’t want Git to automatically convert them when you check out files; however, if a file with CRLF endings accidentally gets introduced, then you may want Git to fix it. You can tell Git to convert CRLF to LF on commit but not the other way around by setting core.autocrlf to input:
$ git config --global core.autocrlf input
This setup should leave you with CRLF endings in Windows checkouts, but LF endings on Mac and Linux systems and in the repository.
7、merge冲突是因为对方删除而导致
Unmerged paths:
(use "git add/rm ..." as appropriate to mark resolution)
deleted by them: src/main/java/com/example/filevisitor/PrintingFileVisitor.java
Resolving this type of conflict is pretty easy. You just have to tell Git whether you want to keep the file in your current branch using command:
$ git add file_name
or if you want to remove it completely:
$ git rm file_name
8、两次git pull
这里的前提假设是你的分支要merge到dev分支
git pull 自己的分支;
Git pull dev
这样可以省好多不必要的麻烦
9、如果有一个文件你做过commit,但是你想忽略掉不做更新了怎么办?
If you want to ignore a file that you've committed in the past, you'll need to delete the file from your repository and then add a
.gitignore rule for it. Using the --cached option with git rmmeans that the file will be deleted from your repository, but will remain in your working directory as an ignored file.首先进入.gitignore 文件所在的目录
$ echo debug.log >> .gitignore
如何查看gitignore项是否生效?
$ git check-ignore -v filename
$ git rm --cached debug.log
rm 'debug.log'
$ git commit -m "Start ignoring debug.log"









